
Retrieval-Augmented Generation Architecture, Use Cases, and Future Impact
An AI system that not only understands and generates text but also retrieves and integrates external knowledge to enhance its responses would be a chef’s kiss. Prompting AI with contextual information can lead to more accurate and relevant outputs and reduce hallucination. AI and LLMs are trained on huge amounts of data, sometimes with the ability to browse the internet and regurgitate and reference almost anything. How can we point our AI in the right direction to create even better responses than now?
This advancement relies on combining generative and retrieval components called Retrieval Augmented Generation. In theory, an LLM is paired with a retrieval mechanism that searches for databases, documents, and web sources for relevant information that is smoothly incorporated into the generative AI output. The results? More accurate, adaptable, and relevant response, significantly impacting the future of artificial intelligence chatbots, and another step closer to general intelligence.
Understanding Retrieval-Augmented Generation (RAG)
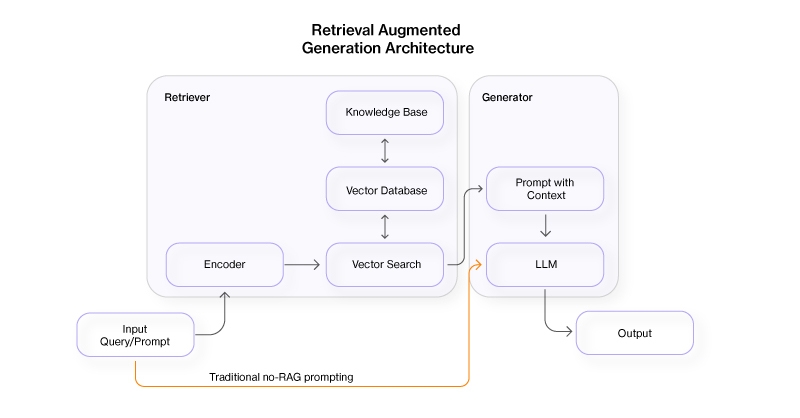
Retrieval-augmented generation integrates two primary components: a retrieval mechanism and a generative model. The retrieval mechanism scours a large corpus of documents to fetch relevant information, which is then used by the generative model to produce coherent and contextually accurate responses.
- Enhanced Accuracy: By leveraging relevant external documents, RAG can provide more accurate and contextually appropriate responses.
- Reduced Hallucinations: Traditional generative models often produce plausible but incorrect information. RAG mitigates this by grounding responses in actual retrieved data.
- Scalability: RAG systems can scale by incorporating larger and more diverse corpora, continually improving their performance as more data becomes available.
Retrieval Mechanism:
- Knowledge Base: The system starts by indexing data, which can include books, articles, and other text sources. The data can be stored in something like a vector database so searching for relevant and adjacent content and topics is more efficient.
- Prompt/Query Encoder: When a prompt/query is received, it is encoded into a vector representation using an encoder model.
- Document Retrieval: This vector is used to search the vector database, retrieving documents that are most relevant to the query. Techniques like dense retrieval (using embeddings) or sparse retrieval (using traditional keyword matching) can be used to find relevant information that can help address the query.
Generative Model:
- Prompt/Query with Context: The retrieved documents/data are fed into the generative model along with the original query creating a super prompt: “With context X, Y, and Z, respond to the prompt.”
- Generative AI or LLM: The generative AI model processes this information to generate a response. This response is enriched by the contextual knowledge provided by the retrieved documents.
Overview of How to Build a RAG-based Chatbot in Python
We won’t have the full code for building a RAG-based LLM, but we can deliver a general overview. There are plenty of other resources on running local LLMs.
- Load the Knowledge Base with data. For this overview, we will use PDF as the data.
- Use a Document Loader like Langchain to connect text-parsable PDFs to your Python project.
- keep all data in a data folder.
- Organize the data into chunks and assign embeddings
- Use Langchain to split the documents into chunks. Smaller sections to make the data easier to reference when we do our contextual input query
- Create unique IDs for each PDF page & chunk
- Generate the embeddings for each PDF page chunk via a local embedding model or an API-based embedding model.
- Create a Vector Database
- Since each PDF page chunk now has unique IDs, we can store the data in a database for reference.
- You can also code your database to update when new data is added or when data is changed.
- Run the RAG model with the LLM
- You can run an LLM locally using Ollama
- Create a prompt template to search the vector database for context based on the prompt:
- Consider the context: {context}. Answer the prompt with the above context: {prompt}
- Use the vector database to find contextual information from relevant PDF page chunks based on the input prompt
- Invoke an LLM using Ollama with the input as the Prompt Template and print the output.
- You can also recall the source of the data by printing the {context} used for that query
One thing to keep in mind when running these LLMs locally is computing power. Using more robust models with more parameters can deliver better results, especially when generating and recalling embeddings from a vector database. Likewise, the more data you store in your project or deployment, the more it requires an increase in computational performance.
Use Cases of RAG
- Customer Support: RAG can revolutionize customer support by providing accurate and contextually relevant answers to customer queries. It can pull from a vast database of previous queries, knowledge bases, and documentation to deliver precise solutions.
- Medical Diagnosis: In the medical field, RAG can assist healthcare professionals by retrieving relevant medical literature and combining it with patient data to offer potential diagnoses and treatment options.
- Research Assistance: Researchers can benefit from RAG by receiving summaries and insights from a wide range of scientific papers, helping them stay updated with the latest advancements and facilitating literature reviews.
- Legal Advisory: RAG can assist legal professionals by retrieving pertinent case laws, statutes, and legal literature, thus helping in the preparation of cases and legal documentation.
Conclusion
Retrieval-augmented generation stands at the forefront of AI research, promising to overcome many of the limitations of traditional generative models. By seamlessly blending retrieval mechanisms with generative capabilities, RAG offers a robust and scalable solution for a wide array of applications. Its impact on foundational LLMs is profound, paving the way for more accurate, reliable, and contextually aware AI systems. As we look to the future, RAG is set to play a pivotal role in the ongoing evolution of artificial intelligence, heralding a new era of smarter, more capable AI.
