.jpg?format=webp)
Introduction
In today's AI landscape, local language models (LLMs) are becoming increasingly important for organizations that prioritize data privacy and reliable performance. DeepSeek R1, an open-source large language model, has emerged as a powerful alternative to cloud-based solutions like ChatGPT. This blog will detail the benefits of using DeepSeek R1 and provide step-by-step instructions for setting it up on your local machine.
The Benefits of an Offline LLM
The benefits of an offline LLM? Offline capabilities.
Unlike ChatGPT and other cloud-based AIs that rely on external servers, DeepSeek is an open-source model that runs completely on your local machine. Whether you're using a workstation or server, DeepSeek operates entirely offline - no internet connection required. This approach democratizes access to AI and brings significant advantages for businesses, researchers, and individuals looking for secure, reliable AI solutions.

Privacy & Security
Privacy is a growing concern with AI models, especially those that require cloud access. Many businesses are reluctant to use AI for sensitive tasks because they are worried how their data is being used.
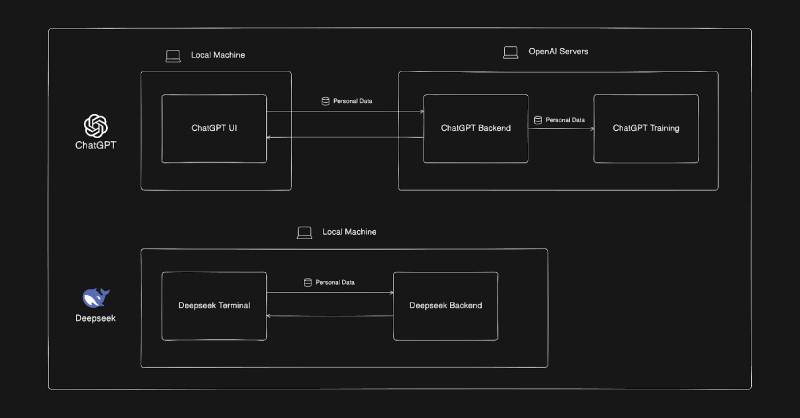
You're a Financial Officer and want to use ChatGPT 4.0 to analyze financial data. When sending data to an external source, even if it’s just a chatbot, there are sensitive data concerns. Sending sensitive data over the internet and having it stored by OpenAI (even if it's just for training) has and always will be a data security risk that most companies aren’t willing to take.
The advantages of an open-source model like DeepSeek include the following:
- Full Data Control – Since DeepSeek runs locally, all data stays on your machine, eliminating the risk of third-party access.
- No External Servers – Unlike GPT-4 sending queries to OpenAI’s servers, DeepSeek processes everything offline on your hardware, making it less prone to leaks for sensitive tasks.
- Safe for Confidential Information – local and open-source LLM like DeepSeek does not store input/outputs and isn't used to train external AI models. When handling domain-specific knowledge like medical records, legal documents, financial data, or personal conversations, all data is stored locally and not shared externally.
- Reduces Security Risks – Cloud-based LLMs can be vulnerable to data breaches, server downtimes, or unauthorized access. DeepSeek, running locally, removes this risk entirely.
Stability & Accessibility
Cloud-based AI models, such as GPT-4, rely on stable internet connections and OpenAI’s infrastructure to function. If the API goes down, the AI becomes unavailable.
- No Internet Required – DeepSeek can be used anytime, anywhere, even in remote locations where internet access is limited or unreliable.
- No API Downtime – Unlike cloud services that experience server outages, DeepSeek is always available on your machine.
- No Latency Issues – Because it runs locally, DeepSeek processes responses instantly, avoiding delays caused by slow API requests.
Cost Savings
AI models like GPT-4 come with recurring costs, often requiring a subscription or pay-per-use API fees. Over time, this can become expensive, especially for businesses with high usage needs.
- No API Fees – Once installed, DeepSeek can be used indefinitely without paying for API tokens or cloud access. There are options to run from one of their cloud servers.
- Reduces Business Costs – Companies relying on AI can cut down on operational expenses by switching to a one-time investment in hardware rather than paying for cloud-based AI services.
- More Predictable Expenses – With DeepSeek running locally, businesses can allocate a fixed budget for hardware upgrades instead of dealing with unpredictable subscription costs.
Customization & Control
One of the biggest drawbacks of GPT-4 and other cloud-based models is that users can’t modify or fine-tune them. DeepSeek, on the other hand, is open-source, allowing full control over its behavior and responses.
- Fine-Tune for Specific Needs – Users can train DeepSeek on custom datasets to optimize it for specific industries like medicine, law, finance, or education.
- Adjust Model Responses – Developers can modify DeepSeek’s behavior, ensuring that the AI aligns with their company's values, industry standards, or ethical guidelines.
- Deploy Locally or on Private Servers – Businesses can run DeepSeek on enterprise servers or on-premise hardware, ensuring compliance with strict data protection policies.
DeepSeek offers people a chance to use AI on their own terms. But don’t take our word for it.
According to ccn.com, big companies from China like Tencent, BYD, and Lenovo are already using DeepSeek in their everyday operations. It’s only a matter of time before other companies catch up.
Setting Up DeepSeek on Your Computer
Now that we’ve covered why DeepSeek is a strong alternative to GPT, let’s walk through how to install and run it offline on your computer.
We’ll be doing this through a Docker container, so that it does not mess up your local machine’s dependencies. However, feel free to do this on a computer you intend to host DeepSeek on.
DeepSeek R1 GPU Requirements
DeepSeek has many flavors to choose from, ranging from 1.5B CPU only models to the full-fat 671B parameter model that is about half a terabyte just to download. The 1.5B and 7B models are great for portable workstations and laptops, whereas the higher parameter models should be hosted on a local server with ample GPU compute.
Model | Parameters | RAM Requirement | VRAM (GPU) Requirement |
DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | 16GB+ RAM | Can Run on CPU |
DeepSeek-R1-Distill-Qwen-7B | 7B | 16GB+ RAM | 8GB+ VRAM recommended |
DeepSeek-R1-Distill-Llama-8B | 8B | 32GB+ RAM | 12GB+ VRAM recommended |
DeepSeek-R1-Distill-Qwen-14B | 14B | 32GB+ RAM | 16GB+ VRAM recommended |
DeepSeek-R1-Distill-Qwen-32B | 32B | 64GB+ RAM | 24GB+ VRAM |
DeepSeek-R1-Distill-Llama-70B | 70B | 128GB+ RAM | 48GB+ VRAM (SabrePC Workstation) |
DeepSeek R1 | 671B | 512GB+ RAM | 1TB+ VRAM (NVIDIA HGX H200) |
Our numbers are just a general estimate. Your expected performance should be factored in. These recommendations should provide a 20-40 tokens per second generation. If you want DeepSeek to output a response quicker, upgrade your hardware, downsize the selected model, or try a quantized version.
For the largest DeepSeek R1 foundational model and running from GPU memory, we recommend a 4U server with 8 or 10 GPU slots kitted with RTX PRO 6000 Blackwell (for good performance), NVIDIA H200 NVLs (for the better performance), or an NVIDIA HGX B200 or H200 (for the best performance). The larger models tend to get a little crazy...
Step 1 - Install Ollama
Ollama is a lightweight runtime that simplifies LLM deployment on local machines. On your terminal -
docker pull ollama/ollama
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
This command will download the official Ollama Docker container image from the Docker registry and start a container using that image.
Step 2 - Pull DeepSeek
For this guide, we’ll pull the smallest version of Deepseek. If you have better hardware, as stated in the prerequisites, feel free to pull a bigger version of DeepSeek. The DeepSeek versions can be found here.
ollama pull deepseek-r1:1.5b
This will download the 1.5 billion parameter model of DeepSeek.
Step 3 - Deploy DeepSeek Locally
After downloading the model, you can run it directly with the command below.
ollama run deepseek-r1:1.5b
After that, you can directly interact with the model just like you would with GPT. You can now even turn off your internet and interact with Deepseek offline.
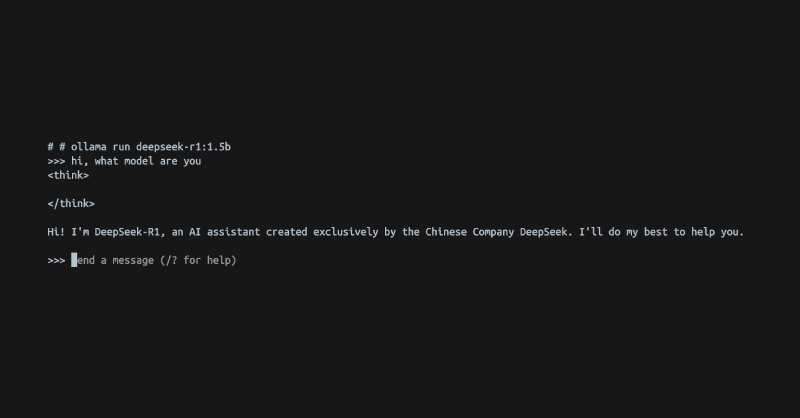
It’s as simple as that! You can even integrate it with any sort of application via APIs. There are also ways to make this UI friendlier!
DeepSeek presents itself as a compelling alternative to GPT models. Its ability to run offline makes it an excellent choice for privacy-focused users, businesses, and developers looking for a cost-effective, stable, and customizable AI solution.
For the hardware to run these powerful models, contact us here at SabrePC. We configure and build high-performance computing workstations, servers, and multi-node racks. We also stock critical HPC components like 128GB RAM modules, workstation-class GPUs, and more.
