
Introduction
Walk into a department store like Costco and you see all the items scattered around in a unorganized fashion. Would you be able to prep for the barbeque you’re hosting? Why are the blenders next to the ribs? Categorizing kitchenware from fruits, proteins from clothes, frozen meals from snacks helps people find what they are looking for.
In data science and analytics, it is the same. Machine learning classification and clustering techniques play a fundamental role in studying your data. These techniques are used to extract meaningful insights and patterns from large datasets, aiding decision-making processes. While classification and clustering share some similarities, they serve different purposes and employ distinct methodologies.
What is Classification in Machine Learning?
Classification is a supervised learning technique that involves categorizing data into predefined classes or categories based on labeled training data. Binary classification where data is bifurcated into only two categories, often True or False like beverage and not beverage. Multi-class classification is where data is put into more than two categories such as distinguishing fruits, vegetables, and protein.
The goal of classification is to develop a model that can accurately assign new, unseen instances to the appropriate class based on the learned patterns from the training data. This way, we can organize our Costco into labeled sections and put items into those aisles.
While classification is a powerful technique, it does have some limitations. These include:
- Dependency on labeled data: Classification algorithms require a large amount of labeled data for training, which can be time-consuming and costly to obtain.
- Sensitivity to feature selection: The choice of features can significantly impact the performance of classification algorithms. Selecting irrelevant or redundant features may lead to inaccurate predictions.
- Imbalanced class distribution: When the classes in the dataset are imbalanced, where one class is more dominant than the others, classification algorithms may struggle to accurately predict the minority class.
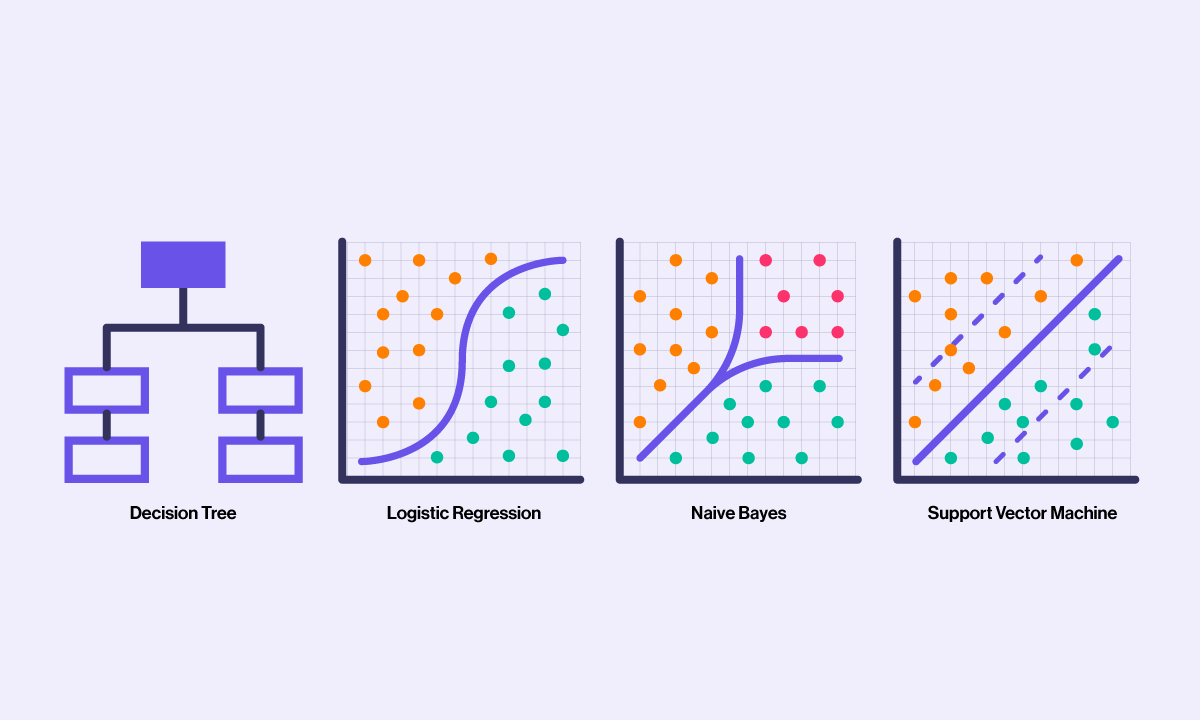
Decision Trees
Decision trees are hierarchical structures that use a series of binary decisions to classify instances. They consist of nodes, branches, and leaves, where each node represents a decision based on a specific feature, branches represent possible outcomes, and leaves represent class labels. Decision trees are easy to interpret and can handle both categorical and numerical data.
Logistic Regression
Logistic regression is a statistical algorithm used for binary classification problems. It models the relationship between the input variables and the probability of a specific outcome using the logistic function. Logistic regression is widely used in various domains and provides interpretable results.
Naive Bayes
Naive Bayes is a probabilistic classification algorithm based on Bayes' theorem. It assumes that the features are independent of each other, which is a naive assumption but simplifies the computations. Naive Bayes classifiers are efficient, especially for text classification tasks.
Support Vector Machines (SVM)
Support Vector Machines (SVM) are powerful classifiers that map the input data to a higher-dimensional feature space to find an optimal hyperplane that separates the classes. SVMs are effective in handling high-dimensional data and can handle both linear and non-linear classification problems.
Applications of Classification in Machine Learning
We can classify our different Costco items into their respective categories: toiletries, beverages, produce, frozen, chips, bread, etc. We can do this either with decision trees if we have each item labeled or use an image recognition. Classification has other numerous applications across various domains. Some common applications include:
- Email spam filtering: Classifying emails as spam or non-spam based on their content and features.
- Disease diagnosis: Predicting the presence of a disease based on symptoms, medical history, and diagnostic test results.
- Sentiment analysis: Classifying text data as positive, negative, or neutral based on the expressed sentiment.
- Credit risk assessment: Assessing the creditworthiness of individuals based on their financial history and other relevant factors.
- Image recognition: Classifying images into different categories based on their visual features.
What is Clustering in Machine Learning?
Clustering is an unsupervised learning technique that involves grouping similar instances together based on their intrinsic characteristics or similarities. Unlike classification, clustering does not rely on predefined class labels but instead discovers patterns and structures within the data. Clustering algorithms aim to find natural groupings or clusters in the dataset.
The goal of clustering is to maximize the similarity of items within the group while distinguishing the various cluster groupings. Clustering helps in identifying hidden patterns, detecting outliers, and understanding the underlying structure of the data. That way we can figure out what food aisles in our Costco should go next to each other based on purchase frequency or similarity. Since fruits and vegetables are often purchased at the same time, they should be near each other in clustering as opposed to fruits and kitchenware.
Clustering also has certain limitations that need to be considered:
- Subjectivity in cluster interpretation: The interpretation of clusters depends on the domain knowledge and the context. Different interpretations can arise based on the different features and distance metrics.
- Sensitivity to initial conditions: Clustering algorithms can produce different results based on the initial starting points or random seeds, leading to potentially different cluster assignments.
- Determining the optimal number of clusters: Selecting the appropriate number of clusters is often a challenging task and requires domain expertise or using evaluation metrics.
K-Means Clustering
K-Means clustering is a popular partition-based clustering algorithm. It partitions the dataset into K clusters, where K is a predefined number. The algorithm iteratively assigns instances to the nearest cluster centroid based on their distances and updates the centroids until convergence.
Hierarchical Clustering
Hierarchical clustering builds a hierarchy of clusters by either starting with each instance in a separate cluster (agglomerative) or starting with all instances in a single cluster and splitting them (divisive). The algorithm merges or splits clusters based on their distances until the desired number of clusters is achieved.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN is a density-based clustering algorithm that groups instances based on their density in the feature space. It defines clusters as dense regions separated by sparser regions. DBSCAN can discover clusters of arbitrary shape and handle noise effectively.
Mean Shift
Mean Shift is an iterative clustering algorithm that assigns instances to clusters by shifting them towards the densest regions of the data. It does not require specifying the number of clusters in advance and can discover clusters of varying densities.
.png)
Applications of Clustering in Machine Learning
Clustering has a wide range of applications in various domains. Some common applications include:
- Customer segmentation: Grouping customers based on their purchasing behavior, demographics, and preferences.
- Anomaly detection: Identifying unusual or abnormal patterns in data that deviate from the norm.
- Document clustering: Organizing documents into clusters based on their content and topic similarity.
- Image segmentation: Partitioning an image into meaningful regions based on visual similarities.
- Recommendation systems: Grouping users with similar preferences to provide personalized recommendations.
Classification vs Clustering: Key Differences
Classification sorts supervised data into labeled datasets whereas clustering finds patterns in unlabeled data so they can be sorted into similar and smaller groups.
Classification and clustering can be used together in some scenarios. Clustering can be used as a preprocessing step to create groups or clusters, and then classification algorithms can be applied within each cluster for further analysis.
Let's go over their training, goals, outputs, how to evaluate their effectiveness, and their application.
- Supervised vs unsupervised: Classification is a supervised learning technique that requires labeled training data, while clustering is an unsupervised learning technique that does not rely on class labels. The differences in labeled and unlabeled data mean that there is a difference in the training of these models.
- Goal: Classification aims to predict the class labels of unseen instances based on learned patterns, while clustering aims to discover inherent patterns and group similar instances together.
- Output: Classification produces class labels or probabilities for each instance, whereas clustering outputs cluster assignments for instances.
- Evaluation: Classification models can be evaluated using metrics such as accuracy, precision, recall, and F1-score, while clustering algorithms are evaluated based on measures like silhouette coefficient or cohesion and separation metrics.
- Application: Classification is commonly used in tasks such as text categorization, sentiment analysis, and image recognition. Clustering finds applications in customer segmentation, anomaly detection, and document clustering, among others.
Choosing Classification and Clustering
Classification and clustering are fundamental techniques in machine learning that serve distinct purposes in data analysis. Classification focuses on predicting class labels based on labeled training data, while clustering aims to discover natural groupings based on similarities in the data. Understanding the differences between classification and clustering is essential for choosing the appropriate technique for specific tasks and leveraging their benefits in various domains.
The type of data is the biggest thing: if you have labeled data, classification is best suited if you already know the potential outputs. For example, you know that you are going to categorize your store by produce, clothing, protein, etc.
If you have unlabeled data or have unlabeled outputs and are just looking for underlying patterns, clustering will help obtain information about the data without assumptions. For example, we can assume the location of our items but once you gathered data for frequency of purchase across types of items, we can see that the rotisserie should go near the raw proteins.
Both techniques are better for certain scenarios that can lend themselves to organizing the data effectively, making segmentation easy for new data points, and grouping data points with statistical reasoning.
