
Examples of NVIDIA’s NGC Docker Container Library
Compared to the original visions for how computers would change the world, we’ve come a long way in terms of portability. On the one hand this is quite literal: the first electronic computers took up the space of a large room, and the paradigm of sedentary computers stored in a dedicated location would remain dominant until the advent of personal computers in the 1970s. The process of miniaturization of electronics and power supplies has led to the current state of computational devices we have today, where the most ubiquitous of these are the most portable such as powerful mobile phones we all carry in our pocket or purse.
This has also led to the nearly cliché phrase comparing modern computation to the space race’s most famous accomplishments in “the [insert name of modern calculator/wristwatch/toy] in your pocket has more computing power than the Apollo lunar lander used to put humans on the moon.” Of course, the Apollo Command and Service Module, the part of the spacecraft that remained in orbit around the moon with the pilot while the other astronauts took the Lunar Module down to goof off on the surface, holds the record for the most isolated human-piloted vehicle. This arguably makes the Apollo Guidance Computer the most portable personal computer of all time.
Anyone that has tried to replicate computational work done by someone else likely already knows that there is far more to portability than physical transportability. Fully reproducing the environment, including all the tools and dependencies, for a given software tool can amount to a substantial portion of the time it takes to develop and use a new tool.
There have been a variety of strategies developed over the years to deal with this problem, and they range across a spectrum from simple to quite involved. On the one end we have virtual environments, and at the extreme other end someone ships you a computer in a box set up exactly to match specifications (more realistically you can expect a computer used in a specific work group to be re-imaged with a common suite of tools used in that group). An example of the latter can be seen in SabrePC's turnkey Deep Learning/AI or Life Science computing solutions that are built in-house and shipped to customers who simply have to unpack it, turn it on and get to work with many of the applications and frameworks they need already installed (and the system optimized for their specific purpose).
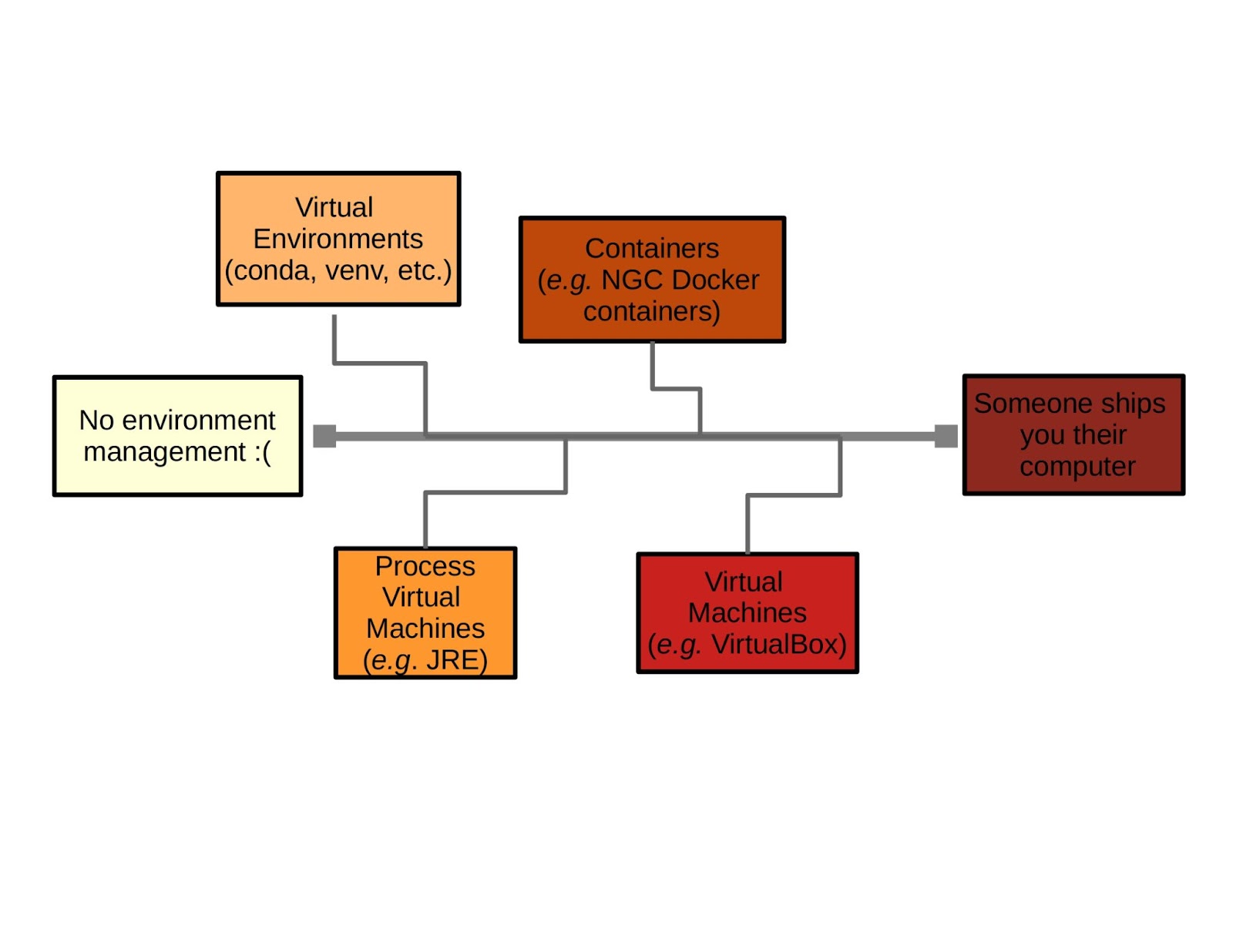
If you regularly experiment with new Python data science and machine learning libraries, you’re probably used to the workflow of setting up a new virtual environment with something like Anaconda or virtualenv, then installing dependencies and finally the tool itself. Setting this up on the command line might look something like the following:
# you've got a new project to try out! cd fresh_repo_clone # make a new virtual environment to manage dependencies virtualenv my_env –python=python3 source my_env/bin/activate # install requirements pip install -r requirements.txt # install in development mode pip install -e # or install from PyPi pip install fresh_repo_clone
Maybe some of the projects you've worked on or with needed a little more in terms of environment management and isolation.
Portability becomes increasingly more important as a project gains traction. If you've built a tool that is only used by a core of dedicated user-developers, they are probably going to be only minimally challenged to build a project from source or install a suite of dependencies compatible with both their machine and the project itself. As the project or product becomes more useful, the user audience may also expand, along with the need for improved portability.
As this happens any friction or pain points related to setting up or troubleshooting dependencies are multiplied by the number of users. Even if the project is well-documented and the user base is savvy enough to ensure everything runs smoothly, any extra overhead (especially repeated in production workflows) becomes problematic. The next step on the spectrum of virtualization is containerization.
Containers offer a middle ground between full-on virtual machines and virtual environments, and in addition to managing dependencies, they can also increase performance. It’s not unusual to see a significant performance boost just by upgrading a library, such as deep learning back-ends PyTorch or TensorFlow.
Encapsulating a project in an up-to-date container gives the container maintainer the control to optimize for performance, where an individual user may be focused on their own experiments and using deprecated tools and leaving an increase in efficiency or speed on the table.
In deep learning in particular, a good bit of advice is to avoid reinventing the wheel, as tempting as that may be. In a blog post by Andrej Karpathy this concept is catchingly referred to as "don’t be a hero." This concept isn't just about not wasting time, it also empowers foundational deep learning advancements such as transfer learning for all types of models and few-shot learning exemplified most prominently by large transformer models in natural language processing. Professionally maintained container libraries are an extension of these principles and offer more capability and less waste through increased portability, improved hardware utilization, and transfer learning from pre-trained models.
NVIDIA develops and maintains the NVIDIA GPU Cloud (NGC) catalog of containers built with Docker technology and specifically optimized for GPU acceleration. In addition to deep learning and data science, NGC has containers designed to support other high performance computing (HPC) applications including molecular dynamics with LAMMPS or GROMACS, quantum electronic structures with Quantum Espresso, and analyzing cryo electron microscopy data with Relion, among others.
NGC containers can be deployed with support from cloud providers including Amazon AWS, Microsoft Azure, and Google GCP, or they can be pulled down and used locally. For many NGC containers, spinning up a local instance is as simple as a docker pull and then a docker run command. In fact, we can spin up an instance designed to showcase the NVIDIA Clara Discovery suite by simply entering the following on the command line (Docker pulls the container image).
docker run –gpus all -it -v tmp:/data -p 5000:5000 nvcr.io/NVIDIA/claracheminformatics_demo:0.1.2
The cheminformatics demo is based on the Clara Discovery NGC container collection. This collections groups together a variety of containers with frameworks and tools supporting drug discovery, from molecular docking with Autodock for virtual screening, to biosequence NLP with BioMegatron and BioBERT, to GROMACS for molecular dynamics.
Use Cases of NGC Containers
In this section we'll take a look at a sample of use cases for NGC containers.
Computer Vision
Neurala is a computer vision startup based in Boston Massachusetts, and an earlier adopter of NGC containers, which they used to develop their Brain Builder video annotation service. Brain Builder is a product that allows users to annotate a few frames of a video to segment a region of interest, and these annotations are then used to fine-tune a pre-trained vision model to differentiate the same objects in subsequent frames. Neurala focuses on visual inspection tasks, for example quality assurance of products coming off a manufacturing line, so we can expect the types of objects being segmented to be machine parts or product containers, but other image objects work too.
The results described by NVIDIA were pretty significant. When developing their Brain Builder product and rolling their own development environments, performance wasn't particularly impressive:
- 3000 milliseconds per frame to fine-tune the model by training on new frame annotations submitted by a user.
- Inference time of about 1000 milliseconds per frame.
After they switched to using an NGC container for their TensorFlow environment (probably based on this one) they saw a marked uptake in product performance.
- About 750 milliseconds per frame during training.
- About 100 milliseconds per frame for inference.
Assuming they didn’t make any changes to their hardware setup at the same time, that’s a speedup of about 4X for training and roughly 10X for inference, all from adopting a professionally maintained NGC container.
You might point out that for machine learning and software engineering in general, the most important and valuable asset is usually development time, not compute time. It's harder to quantify exactly what they may have saved in terms of engineering time, but Abhishek Gaur, a deep learning engineer featured in the video, estimated an extra 3 hours of work per day for himself personally to meet the product deadline. So in this case we can estimate engineering time savings of about 37.5%.
Text-to-Speech
DeepZen is a London-based startup working on deep learning text-to-speech synthesis. Their primary differentiation from existing products is the smooth and natural emotional context of their speech output (skip to 0:31 for a compelling demo in the video).
Unlike traditional text-to-speech synthesis, which strings together words that are generated individually, DeepZen generates larger blocks of text together with a cohesive emotional context. The details aren’t specified but the “emotional labels” they use to generate natural-sounding speech can be thought of as driving the learning of “sentiment neuron” activations for speech.
DeepZen didn’t specify quantitative speedups, but describe the qualitative convenience of using NGC containers, particularly to easily switch between using TensorFlow and PyTorch frameworks.
AI Music
Originally this section was going to highlight using NGC containers for fundamental research, but I instead found an interesting and more creative application (but do check out the videos describing the MATLAB NGC container and general description of NGC containers for research). This project was completed and described by even-keeled musician and artificial intelligence consultant Tristan Behrens.
Tristan describes adding NGC containers to his generative music workflow to add a new capability, namely the addition of vocals. The result is the single Hexagon (featuring Flowtron), which you can listen to here.
The project used NGC containers set up with pre-trained models WaveGlow and Flowtron to generate spectrograms and audio vocals, respectively, addressing a similar problem to that described in the DeepZen case study above. Conventional text-to-speech sounds too robotic, doesn’t tie words together into cohesive wholes, and lacks emotional context. Solving these problems from scratch is likely to be too challenging for a generative musician, with a day-job besides, but as Tristan shows it’s relatively easy to put together with the help of the right NGC container.
Conclusions
The NGC Container catalog provides a variety of containers specifically designed by NVIDIA to maximally utilize NVIDIA hardware. The containers are grouped into collections based on tools belonging to shared application spaces, and NGC containers integrate Helm charts as an additional tool for managing projects. In addition to supporting Docker containers and integrating into the Docker ecosystems, NGC in general supports singularity containers as well. Singularity is another popular choice for containerization, especially in high-performance computing applications.
NGC containers aren’t the only source for officially supported containers, with Docker Hub being probably the most recognized option. There is also the (archived) Singularity Hub, and a collection of container recipes in the Singularity Container Catalog. In some cases JupyterHub may be a compelling option for managing work environments, but setting up a JupyterHub instance for your workgroup or institution entails more work and JupyterHub instances aren’t really intended to be set up on a local machine (they may introduce security vulnerabilities), but they can be deployed on an on-premise server.
Among the myriad sources for standardized and professionally developed containers, NGC containers are a compelling option. In particular they offer relatively easy setup (saving on developer time) and can be expected to be optimized well for NVIDIA GPU acceleration (saving on compute time). They are integrated into a variety of cloud service providers, and they are also comparatively simple to use locally, which is more flexible than some other options available. Taken together, NGC containers and the supporting ecosystem offer convenience that can accelerate a given project or make some projects possible that would otherwise be prohibitively complicated to pull off.
If you have any questions about NVIDIA's Docker container library or any other NGC containers feel free to contact us and we will help you get started.
In the meantime, you can find other articles and comparisons elsewhere on the SabrePC blog. Keep a lookout for more helpful articles that will be on the way soon.